 LLM复读机产生的原因以及对应的解决方案
LLM复读机产生的原因以及对应的解决方案1. 背景
关于LLM复读机问题,本qiang~在网上搜刮了好几天,结果是大多数客观整理的都有些支离破碎,不够系统。
因此,本qiang~打算做一个相对系统的整理,包括LLM复读机产生的原因以及对应的解决方案。
2. LLM复读机示例
示例1:短语级别的重复
User: 你喜欢北京么? AI: 北京是中国的首都,有很多名胜古迹,如长城,故宫,天坛等,我十分喜欢喜欢喜欢喜欢….. |
示例2:句子级别的重复
User: 你喜欢北京么? AI: 北京是中国的首都,有很多名胜古迹,如长城,故宫,天坛等,我十分热爱北京,我十分热爱北京,我十分热爱北京,….. |
3. LLM复读机原因
本文主要参考了清华大学的论文《Learning to Break the Loop: Analyzing and Mitigating Repetitions for Neural Text Generation》,文中详细介绍了LLM产生复读的原因。论文的前提假设是LLM的解码均为贪心解码(greedy decoding),即每次生成的token选择词表中概率最大的token。
结论如下:
(1) LLM趋向于提高重复先前句子的概率
特别地,即使仅出现一条句子级的上下文重复,重复的概率在大多数情况下也会增加。产生这种现象的原因可能是LLM对上下文非常有信心,当先前的token共享同一个句子级的上下文时,模型会学到一条捷径,直接复制该token。
另一种解释就是Inudction Head机制,即模型会倾向于从前面已经预测word里面挑选最匹配的词。
举个例子来说明下,示例1中的第二个’喜欢’共享了同句子中的’我十分喜欢’,因此模型直接会将’喜欢’拷贝至’我十分喜欢’,进而生成’我十分喜欢喜欢’
(2) 自我强化效应(self-reinforcement effect)
重复的概率几乎随着历史重复次数的增加而单调增加,最终,重复概率稳定在某个上限值附近。
一旦生成的句子重复几次,模型将会受困于因自我强化效应引起的句子循环。
下图是论文中的图,意思是随着重复次数的增加,’general’一词的概率几乎单调增加,最终趋于稳定。其中红柱表示生成相同token的概率,蓝色表示最大概率。
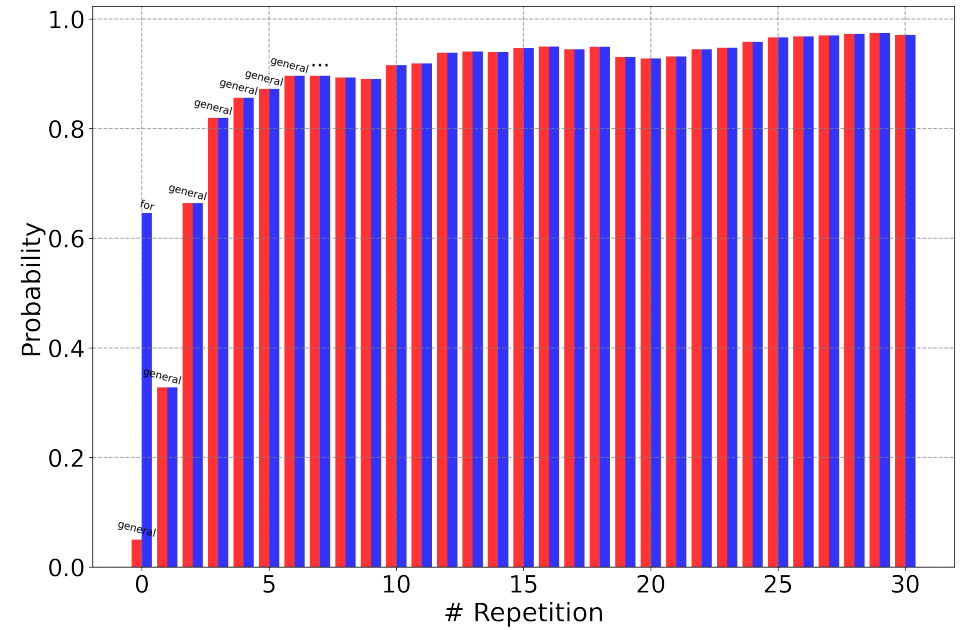
(3) 初始概率较高的句子通常具有较强的自我强化效应。
4. 如何解决
目前针对LLM重复生成的问题,主要有两种策略,一种是基于训练思想,一种是基于解码策略。
4.1 基于训练策略
整体思想就是通过构造伪数据,即短语重复、句子重复等伪数据,如短语或句子重复N遍,然后设计重复惩罚项来抑制大模型生成重复句子。
论文中提出了DITTO方法即采用了此策略,DITTO全称为PseuDo RepetITion PenalizaTiOn(不得不佩服算法名称的设计精美~)。
重复惩罚项通过设计损失函数来达成,其中是惩罚因子λ,论文中提到,对于开放式生成,推荐取值为0.5,对于总结摘要类任务,取值为0.9性能更好。

代码分析:
DITTO损失函数计算的代码块位于中”DITTO/fairseq/custom/repetetion_penalty_accum_loss.py”方法中,大体流程简要分析如下:
# 构造随机重复的特征 sample, P, L, N, K = self.re_orgnize_sentence(sample) # 基于构造的重复特征进行预测 net_output = model(**sample['net_input']) ………. ## 计算损失函数 # 获取重复的基线概率信息 gt_probs, mask, valid_tokens = self.obtain_rep_baseline_prob(model.get_targets(sample, net_output), target_probs.detach(), P, L, N, K) # 损失函数公式套用 one_minus_probs = torch.clamp((1.0 - torch.abs((target_probs - gt_probs*self.rep_reduce_gamma))), min=1e-20) loss = -torch.log(one_minus_probs) * mask loss = loss.sum() |
此外,基于训练的策略还有其他方式,如UL(unlikelihood training)和SG(straight to gradient),论文链接可以参考第6小节。
4.2 基于解码策略
基于解码策略包含诸多方法,如beam search, random search(topK, topP), 温度, ngram等。
(1) 集束搜索(beam search)
针对贪心策略的改进,思想就是稍微放宽一些考察范围。即,在每一个时间步,不再只保留当前分数最高的1个输出(贪心策略),而是保留num_beams个,当num_beams=1时,集束搜索就退化成了贪心搜索。
(2)random search(topK, topP)
topK即从概率最高的K个token中进行筛选,即允许其他高分tokens有机会被选中
topP将可能性之和不超过特定值的top tokens列入候选名单,topP通常设置较高的值,目的是限制可能被采样的低概率token的长尾
(3) 温度T
较低的温度意味着较少的随机性,温度为0将始终产生相同的输出,较高的温度意味着更多的随机性,可以帮助模型给出更有创意的输出。
基于解码的策略墙裂建议直接查阅transformers框架中的实现方法,本qiang~切身体会,阅读源码确实能愉悦身心~
5. 总结
一句话足矣~
本文主要展开解读了LLM的复读机问题,并参考相关论文,给出基于训练策略和基于解码策略的解决手段,相信客官们清楚该问题了。
静待下一次的LLM知识点分享~
6. 参考
(1) DITTO:
(2) UL:
(3) SG:
(4) beam search:
(5) random search(topK, topP), 温度: https://zhuanlan.zhihu.com/p/613428710