1,聚合
聚合(aggregate)主要用于计算数据,类似sql中的sum()、avg()。
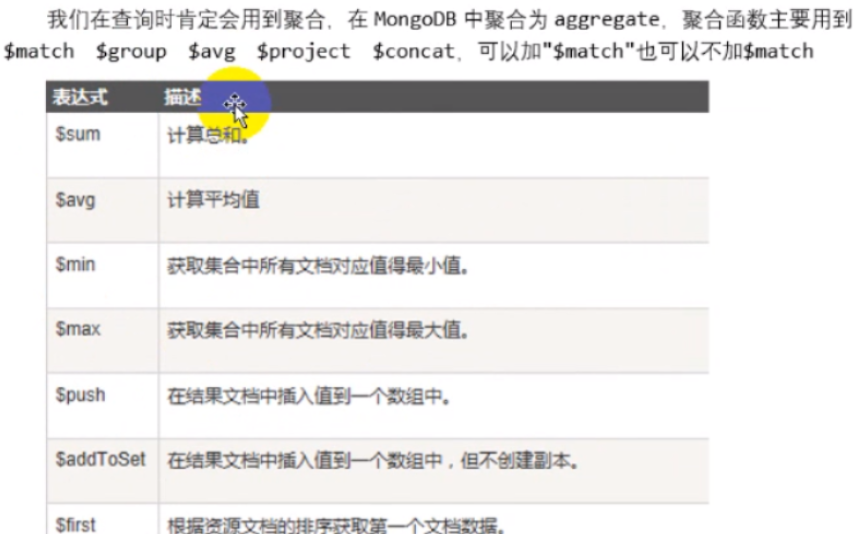
![]()
常用的表达式如上图。
1.1,aggregate 语法
语法: db.集合名称.aggregate([{管道:{表达式}}])

常用的管道:

1.2,$match 和 $group

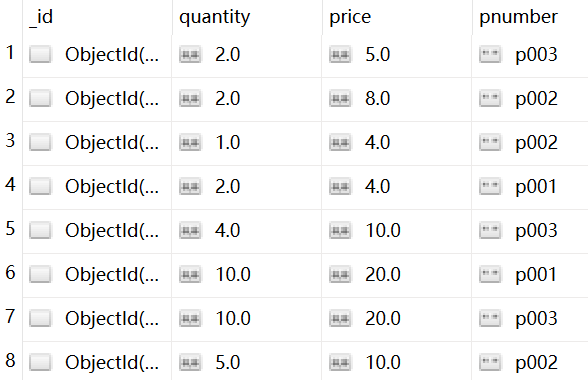
往集合 items 中先插入数据
db.items.insert(
[
{quantity:2,price:5.0,pnumber:"p003"},
{quantity:2,price:8.0,pnumber:"p002"},
{quantity:1,price:4.0,pnumber:"p002"},
{quantity:2,price:4.0,pnumber:"p001"},
{quantity:4,price:10.0,pnumber:"p003"},
{quantity:10,price:20.0,pnumber:"p001"},
{quantity:10,price:20.0,pnumber:"p003"},
{quantity:5,price:10.0,pnumber:"p002"}
]
)查看可视化工具插入的结果如下:
例1:

查询 pnumber:"p001" , 再来看语法 :db.集合名称.aggregate([{管道:{表达式}}])
db.items.aggregate([{"$match":{"pnumber":"p001"}}])
例2:
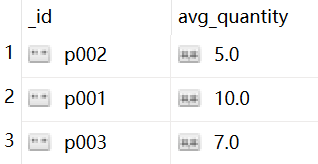
查询price 大于8的 quantity ,以平均值 avg_quantity表示,并按 pnumber分组。所以分组字段是 $pnumber,平均值avg_quantity,avg_quantity是新的字段名,聚合操作符是 $avg。
db.items.aggregate([
{"$match":{"price":{"$gt":8}}},
{"$group":{"_id":"$pnumber","avg_quantity":{"$avg":"$quantity"}}}
])
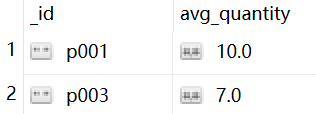
例3:
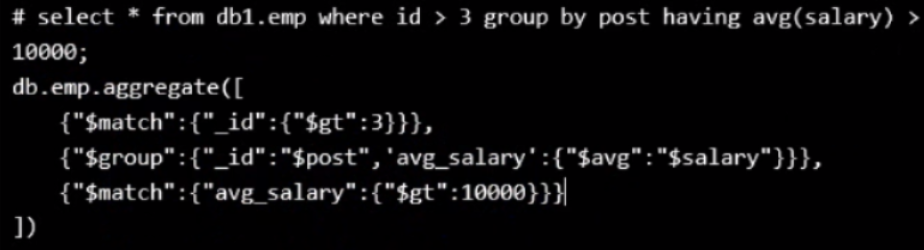
查询 price大于8的quantity,以平均值 avg_quantity 表示,并过滤出平均值大于5的avg_quantity。前半句话是上个例子的,过滤出 是用 $match。
db.items.aggregate([
{"$match":{"price":{"$gt":8}}},
{"$group":{"_id":"$pnumber","avg_quantity":{"$avg":"$quantity"}}},
{"$match":{"avg_quantity":{"$gt":5}}}
])
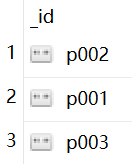
例4:

按 pnumber分组
db.items.aggregate([
{"$group":{"_id":"$pnumber"}}
])
按 quantity 和 price 分组
db.items.aggregate([
{"$group":{"_id":{"quantity":"$quantity","price":"$price"}}}
])截了部分屏

1.3,聚合操作符($sum,$avg,$max,$min,$first,$last)
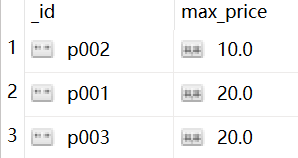
例1($max):

按 pnumber 分组,并求出 每组 price的最大值max_price
db.items.aggregate([
{"$group":
{"_id":"$pnumber","max_price":{"$max":"$price"}
}
}
])
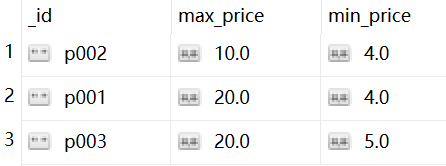
例2($min):

按 pnumber分组,并求出每组 price 的最大值 max_price,最小值 min_price
db.items.aggregate([
{"$group":
{"_id":"$pnumber","max_price":{"$max":"$price"},"min_price":{"$min":"$price"}
}
}
])

这个把上面写的 $max,$min一替换就行。
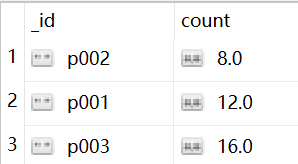
例3($sum):

按pnumber分组,并计算每组的 quantity的总和 count,并按count升序排。这里用了 $sort,注意要在分组完才能 $sort(看好格式)。
db.items.aggregate([
{"$group":
{"_id":"$pnumber","count":{"$sum":"$quantity"}},
},
{"$sort":{"count":1}}
])
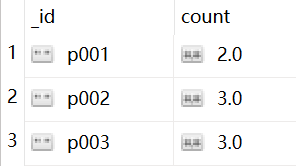
例4:

查询分组后 每个 pnumber 出现的次数,并按升序排
db.items.aggregate([
{"$group":
{"_id":"$pnumber","count":{"$sum":1}},
},
{"$sort":{"count":1}}
])
例5($addToSet,$push):
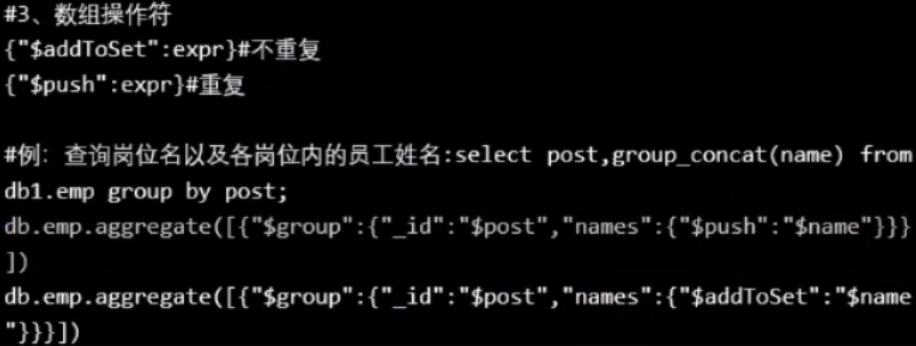
按 pnumber 分组,并查出各 pnumber内的price ,price可以重复 (用 $push)
db.items.aggregate([
{"$group":
{"_id":"$pnumber","prices":{"$push":"$price"}}
}
])结果 是因为添加的数据不太好,所以看不出有没有重复还是重复了。

按 pnumber 分组,并查出各 pnumber内的price ,price不可以重复 (用 $addToSet)
db.items.aggregate([
{"$group":
{"_id":"$pnumber","prices":{"$addToSet":"$price"}}
}
])
1.4,投射 ($project),$add
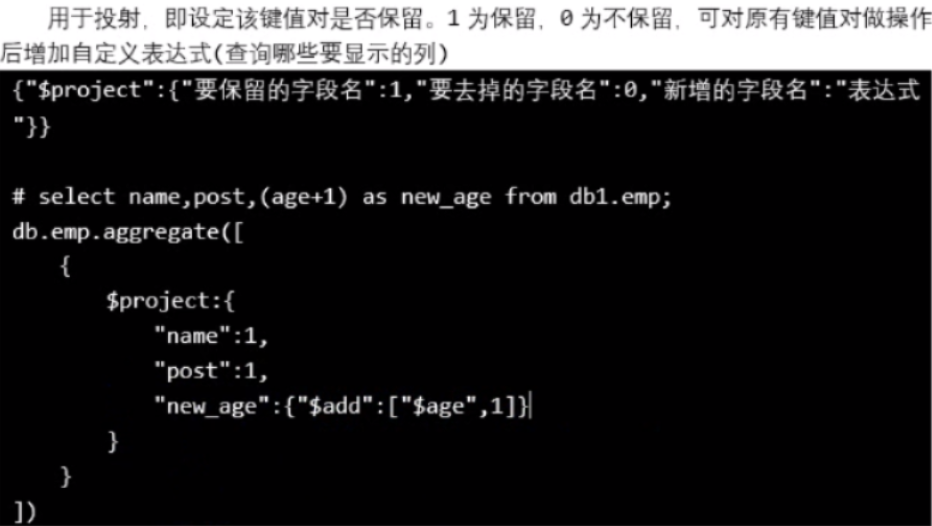
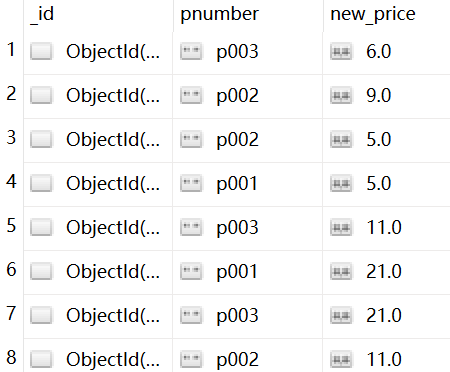
只保留 _id 和 pnumber,新增 new_price,new_price 就是让 price加1(用到了 $add)
db.items.aggregate([
{
$project:{"_id":1,"pnumber":1,"new_price":{"$add":["$price",1]}
}
}
])
1.5,排序($sort),限制($limit),跳过($skip)

例1:
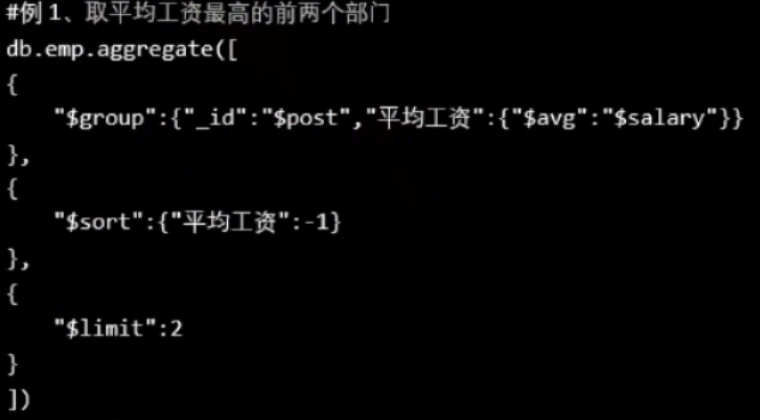
取平均价格最贵的前两个pnumber,所以是按pnumber分组($group),再降序排($sort),再限制是前两个($limit)。
db.items.aggregate([
{"$group":{"_id":"$pnumber","平均价格":{"$avg":"$price"}}
},
{"$sort":{"平均价格": -1}
},
{"$limit":2
}
])
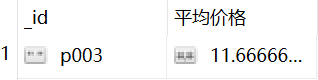
例2:
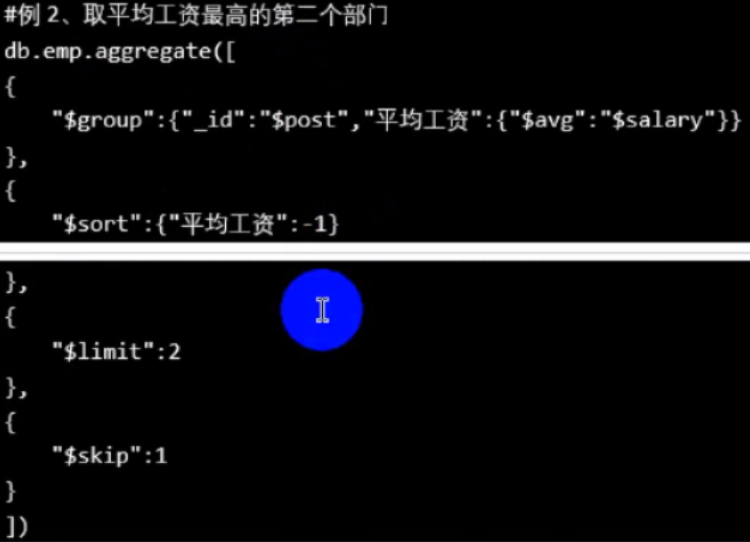
取平均价格最贵的第二个 pnumber,就是在上个例子的基础上,跳过1个, $skip:1
db.items.aggregate([
{"$group":{"_id":"$pnumber","平均价格":{"$avg":"$price"}}
},
{"$sort":{"平均价格": -1}
},
{"$limit":2
},
{"$skip":1
}
])
1.6,随机获取,$sample
db.items.aggregate([
{$sample: {size:3}}
])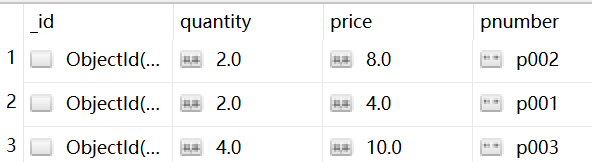
再点运行,就出来不一样的结果
1.7,截取($substr),拼接($concat),转小写($toLower),转大写($toUpper)

例1:
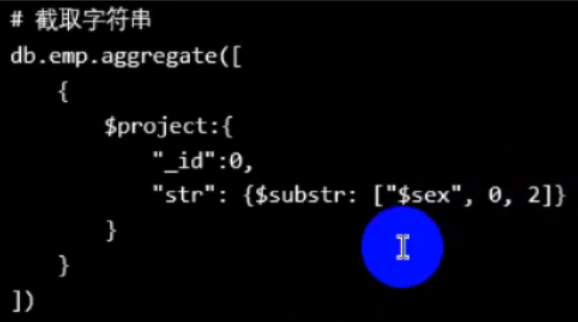
把 pnumber 的下标为 0到2 位置的 截出来,_id 隐藏
db.items.aggregate([
{
$project:{"_id":0,"str": {$substr: ["$pnumber",0,2]}
}
}
])因为截取是 左闭右开的截,所以显示是两个字符。

例2:
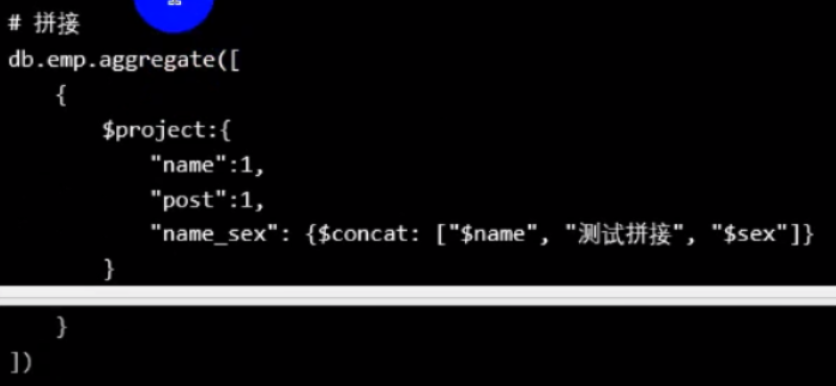
把 pnumber 字段下的内容 和 "测试" 拼接起来
db.items.aggregate([
{"$project":{"_id":0,"str": {"$concat": ["$pnumber","测试"]}
}
}
])
例3:

将pnumber的 英文转换为大写
db.items.aggregate([
{"$project":{"pnumber":{"$toUpper":"$pnumber"}}
}
])