系列
什么是 Sharded Cluster(分片集群)
Sharded Cluster(分片集群)是实现数据库分片的集群。数据库分片是跨多台机器存储大型数据库的过程。这是通过在多个 Postgres 主实例之间分隔表行来实现的。这种方法提供了将数据库扩展到多个实例的能力,既有利于读取和写入吞吐量,也有利于在不同实例之间分离数据以实现安全性和/或满足法规或合规性要求。
Sharded Cluster 是如何实现的
一个分片集群是通过构造一个称为协调器的SGCluster 和一个或多个称为shards(分片) 的 SGCluster 来实现的。顾名思义,协调器协调实际存储数据的 shards(分片) 。StackGres 负责按照 SGShardedCluster 中设置的规范创建相关的 SGCluster。
SGShardedCluster 可以定义分片的类型(即所使用的内部分片实现)和要分片的数据库。
目前只有一个实现可用,这是通过使用Citus 扩展提供的。
创建一个基本的 Citus Sharded Cluster
创建SGShardedCluster 资源:
cat << EOF | kubectl apply -f -
apiVersion: stackgres.io/v1alpha1
kind: SGShardedCluster
metadata:
name: cluster
spec:
type: citus
database: mydatabase
postgres:
version: '15'
coordinator:
instances: 2
pods:
persistentVolume:
size: '10Gi'
shards:
clusters: 4
instancesPerCluster: 2
pods:
persistentVolume:
size: '10Gi'
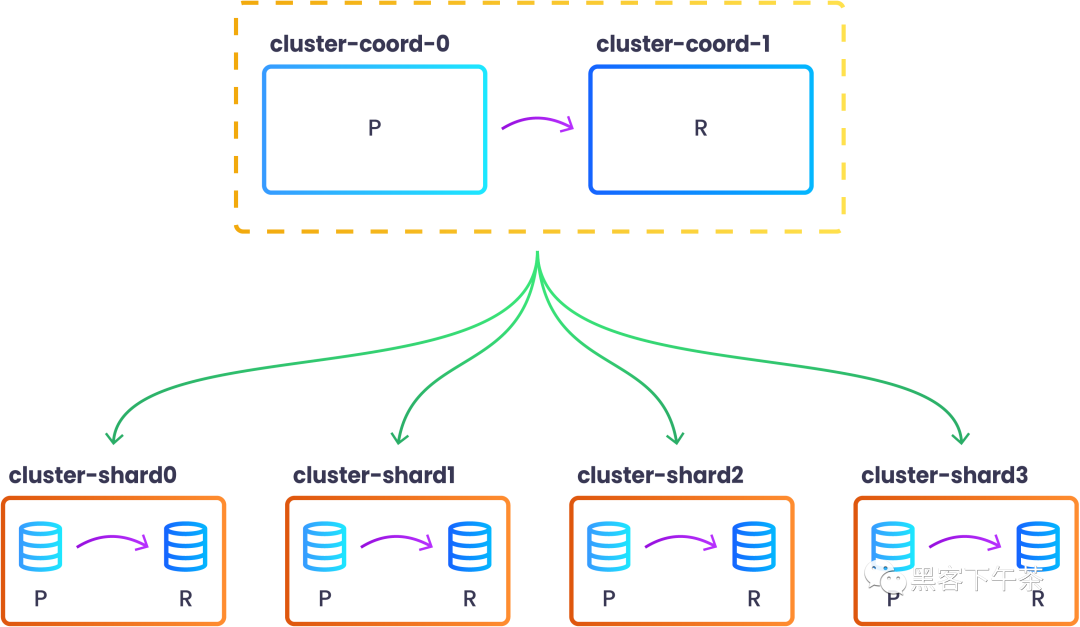
EOF此配置将创建一个包含 2 个 pod 的coordinator(协调器)和4 个 shards(分片),每个分片包含 2 个 pod。
所有 Pod 就绪后,您可以通过发出以下命令来查看新创建的分片集群的拓扑:
kubectl exec -n my-cluster cluster-coord-0 -c patroni -- patronictl list
+ Citus cluster: cluster --+------------------+--------------+---------+----+-----------+
| Group | Member | Host | Role | State | TL | Lag in MB |
+-------+------------------+------------------+--------------+---------+----+-----------+
| 0 | cluster-coord-0 | 10.244.0.16:7433 | Leader | running | 1 | |
| 0 | cluster-coord-1 | 10.244.0.34:7433 | Sync Standby | running | 1 | 0 |
| 1 | cluster-shard0-0 | 10.244.0.19:7433 | Leader | running | 1 | |
| 1 | cluster-shard0-1 | 10.244.0.48:7433 | Replica | running | 1 | 0 |
| 2 | cluster-shard1-0 | 10.244.0.20:7433 | Leader | running | 1 | |
| 2 | cluster-shard1-1 | 10.244.0.42:7433 | Replica | running | 1 | 0 |
| 3 | cluster-shard2-0 | 10.244.0.22:7433 | Leader | running | 1 | |
| 3 | cluster-shard2-1 | 10.244.0.43:7433 | Replica | running | 1 | 0 |
| 4 | cluster-shard3-0 | 10.244.0.27:7433 | Leader | running | 1 | |
| 4 | cluster-shard3-1 | 10.244.0.45:7433 | Replica | running | 1 | 0 |
+-------+------------------+------------------+--------------+---------+----+-----------+请注意,pg_dist_node 表的groupid 列与上面的 Patroni Group 列相同。特别是,标识符为0 的组是 coordinator(协调器) 组(coordinator 的shouldhaveshards 列设置为f)。
创建一个自定义的生产级 Citus Sharded Cluster
Sharded Cluster 自定义配置
有关分片集群配置的更多详细信息,请参阅一节。具体来说,您将在my-cluster 命名空间中创建以下自定义资源:
SGInstanceProfile(k8s pods 自定义配置)
- 一个名为
size-small的apiVersion: stackgres.io/v1 kind: SGInstanceProfile metadata: namespace: demo name: size-small spec: cpu: "4" memory: "8Gi"
SGPostgresConfig(postgres 自定义配置)
- 一个名为
pgconfig1的apiVersion: stackgres.io/v1 kind: SGPostgresConfig metadata: name: postgresconf spec: postgresVersion: "11" postgresql.conf: password_encryption: 'scram-sha-256' random_page_cost: '1.5' shared_buffers: '256MB' wal_compression: 'on'
SGPoolingConfig(pgBouncer 自定义配置)
- 一个名为
poolconfig1apiVersion: stackgres.io/v1 kind: SGPoolingConfig metadata: name: pgbouncerconf spec: pgBouncer: pgbouncer.ini: pgbouncer: max_client_conn: '2000' default_pool_size: '50' databases: foodb: max_db_connections: 1000 pool_size: 20 dbname: 'bardb' reserve_pool: 5 users: user1: pool_mode: transaction max_user_connections: 50 user2: pool_mode: session max_user_connections: '100'
SGObjectStorage(s3 数据备份自定义配置)
- 一个名为
backupconfig1的apiVersion: stackgres.io/v1beta1 kind: SGObjectStorage metadata: name: objectstorage spec: type: s3Compatible s3Compatible: bucket: stackgres region: k8s enablePathStyleAddressing: true endpoint: http://my-cluster-minio:9000 awsCredentials: secretKeySelectors: accessKeyId: key: accesskey name: my-cluster-minio secretAccessKey: key: secretkey name: my-cluster-minio
SGDistributedLogs(分布式日志 server 配置)
- 一个名为
distributedlogs的apiVersion: stackgres.io/v1 kind: SGDistributedLogs metadata: name: distributedlogs spec: persistentVolume: size: 10Gi
配置 SQL 启动脚本
最后但同样重要的是,StackGres 允许您包含几个managedSql 脚本,以便在启动时执行集群操作。
在这个例子中,我们使用 Kubernetes secret 创建一个 Postgres 用户,并使用 Citus 创建一个分片表:
kubectl -n my-cluster create secret generic pgbench-user-password-secret \
--from-literal=pgbench-create-user-sql="create user pgbench password 'admin123'"然后我们在 中引用这个 secret:
cat << EOF | kubectl apply -f -
apiVersion: stackgres.io/v1
kind: SGScript
metadata:
namespace: my-cluster
name: cluster-scripts
spec:
scripts:
- name: create-pgbench-user
scriptFrom:
secretKeyRef:
name: pgbench-user-password-secret
key: pgbench-create-user-sql
- name: create-pgbench-tables
database: mydatabase
user: pgbench
script: |
CREATE TABLE pgbench_accounts (
aid integer NOT NULL,
bid integer,
abalance integer,
filler character(84)
);
- name: distribute-pgbench-tables
database: mydatabase
user: pgbench
script: |
SELECT create_distributed_table('pgbench_history', 'aid');
EOF脚本由之前创建的 Secret 和内联的 SQL 指令定义。
SGScript 将在分片集群的协调器的managedSql 定义中被引用,如下所示。
请注意,我们同样可以在配置映射中定义 SQL 脚本,但是,由于 password 表示凭据,因此我们使用的是 secret。
创建 Citus 集群
执行了所有必要的步骤来创建我们的 StackGres 集群。
创建 SGShardedCluster 资源:
cat << EOF | kubectl apply -f -
apiVersion: stackgres.io/v1alpha1
kind: SGShardedCluster
metadata:
namespace: my-cluster
name: cluster
spec:
type: citus
database: mydatabase
postgres:
version: '15.3'
coordinator:
instances: 2
sgInstanceProfile: 'size-small'
pods:
persistentVolume:
size: '10Gi'
configurations:
sgPostgresConfig: 'pgconfig1'
sgPoolingConfig: 'poolconfig1'
managedSql:
scripts:
- sgScript: cluster-scripts
shards:
clusters: 3
instancesPerCluster: 2
sgInstanceProfile: 'size-small'
pods:
persistentVolume:
size: '10Gi'
configurations:
sgPostgresConfig: 'pgconfig1'
sgPoolingConfig: 'poolconfig1'
configurations:
backups:
- sgObjectStorage: 'backupconfig1'
cronSchedule: '*/5 * * * *'
retention: 6
distributedLogs:
sgDistributedLogs: 'distributedlogs'
prometheusAutobind: true
EOF注意,每个资源都有自己的name,并在 StackGres 分片集群定义中被引用。
创建 CR 的顺序与成功创建分片集群相关,即在创建依赖资源之前创建所有必要的resources、secrets 和permissions。
另一个有用的配置是 定义。
此参数自动启用对分片集群的监控。
如果我们已经在 Kubernetes 环境中安装了 Prometheus operator。