前言:
Oracle常用正则表达式函数主要以下5个:
- REGEXP_LIKE:与LIKE的功能相似;
- REGEXP_SUBSTR :与SUBSTR的功能相似;
- REGEXP_INSTR :与INSTR的功能相似;
- REGEXP_REPLACE :与REPLACE的功能相似;
- REGEXP_COUNT :与COUNT的功能相似;
常用的正则表达式匹配符有以下运算符,本文重点来阐述“|”指定多个选项,容易被忽视的问题。

一、正则表达式用法(Regexp_Like为例)
Regexp_Like()函数 模糊匹配。
1、语法规则
regexp_like(source_string,pattern[match_parameter])
2、注释
- source_string:传入的字符串,可以是常量,也可以是某个值类型为串的列;
- pattern:要进行匹配的字符串;
- match_parameter:文本量,进一步订制搜索,取值如下:
- ‘i’ 用于不区分大小写的匹配。
- ‘c’ 用于区分大小写的匹配。
- ‘n’ 允许将句点“.”作为通配符来匹配换行符。如果省略该参数,句点将不匹配换行符。
- ‘m’ 将源串视为多行。即将“^”和“$”分别看做源串中任意位置任意行的开始和结束,而不是看作整个源串的开始或结束。如果省略该参数,源串将被看作一行来处理。
如果取值不属于上述中的某个,将会报错。如果指定了多个互相矛盾的值,将使用最后一个值。如’ic’会被当做’c’处理。
省略该参数时:默认区分大小写、句点不匹配换行符、源串被看作一行。
3、实例
代码:
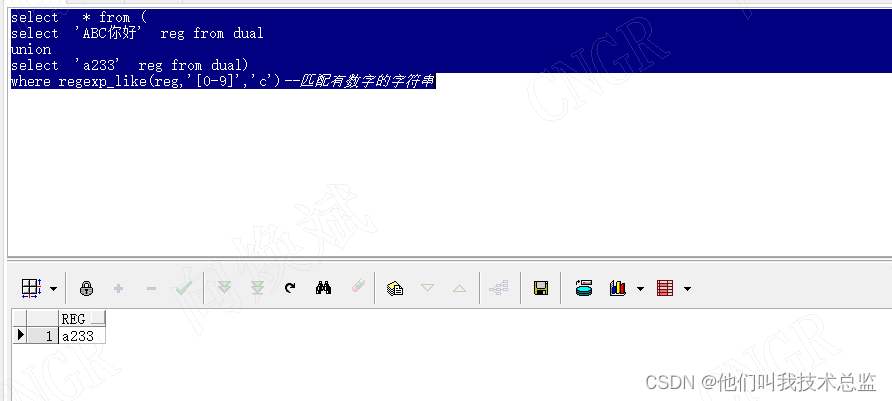
select * from ( select 'ABC你好' reg from dual union select 'a233' reg from dual) where regexp_like(reg,'[0-9]','c')--匹配有数字的字符串
效果:
解析:
可以看到正则表达式,通过后面的'[0-9]'的规则来获取我们想要的数据。
二、正则表达式优先级的注意点
当我们使用REGEXP_REPLACE将多个表达式的数据替换时,这时候我们要考虑替换规则有没有类似项,比如REGEXP_REPLACE(reg,'-BL|-BL1')即替换掉字符串reg里面包含-BL或者-BL1的字符串,此时如果我们按这种写法REGEXP_REPLACE(reg,'-BL|-BL1'),实际效果是只会替换掉-BL,因为oracle会按照替换规则的顺序来执行,如果满足了第一个条件,后面的就不会再去执行了,这也是为了加快了程序的处理速度,但同时也会造成我们常常忽略的问题。
好的,我们来看看下面的具体案例吧。
代码:
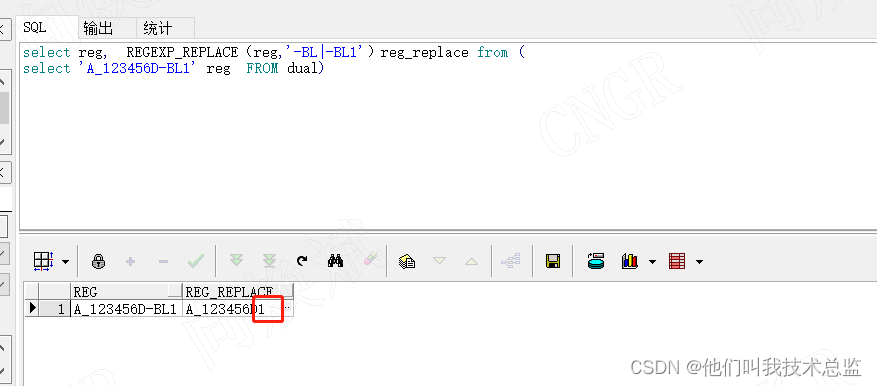
select reg, REGEXP_REPLACE(reg,'-BL|-BL1')reg_replace from ( select 'A_123456D-BL1' reg FROM dual)
效果:
解析:
因为正则表达式,默认会按顺序执行,此时正则表达式,-BL满足规则了,就不会执行-BL1了,因此就会得到的结果是对应的REG字符串里面替换后还会多出了一个1。
三、解决方案
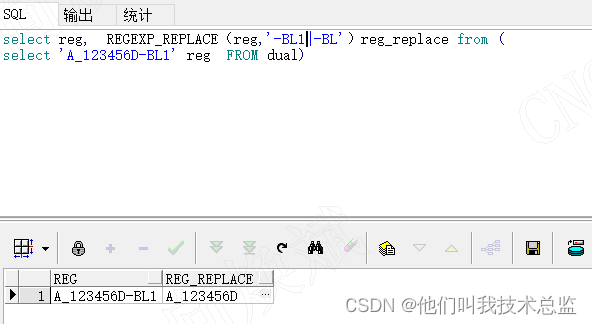
现实情况下,我们往往会有很多替换规则,少则几个,多则好几百,如果我们用replace函数估计要嵌套几百次,估计你会直摇头吧,虽然regexp_replace可以一次性将多个规则写在一起,但是我们还是要注意上述提到的优先级的问题。因此我们需要将相同的部分放到最后,如上面说到的“-BL”此时就能达到我们的需求了。
扩展:
我们来看个现实的案例。当面对168个规则时我们会遇到哪些问题。
1、正则表达式过长
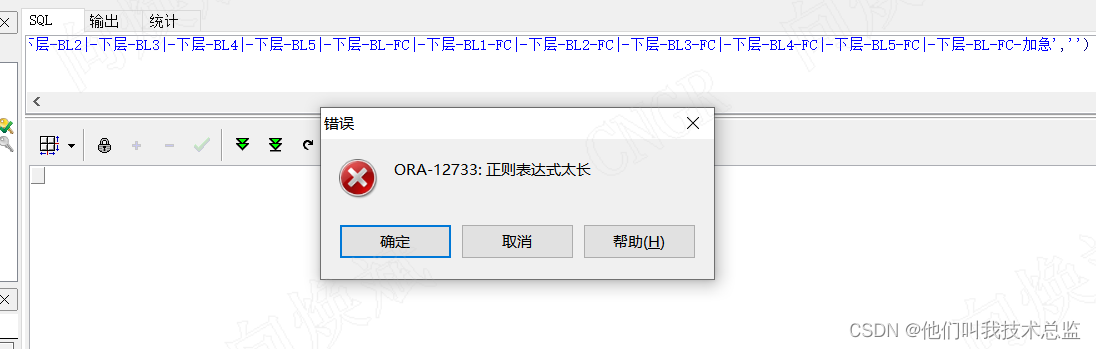
解决方法:嵌套多个正则表达式 ,像竹笋一样多叠几层即可。
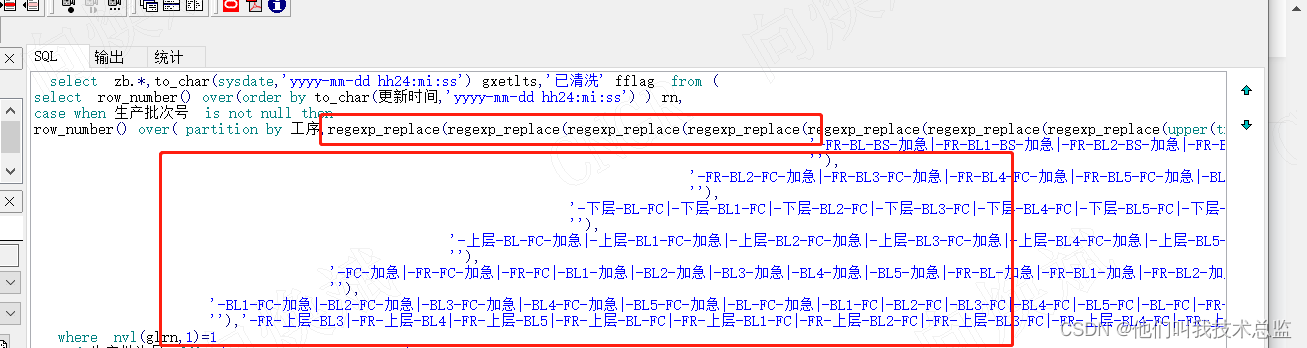
2、替换规则失效
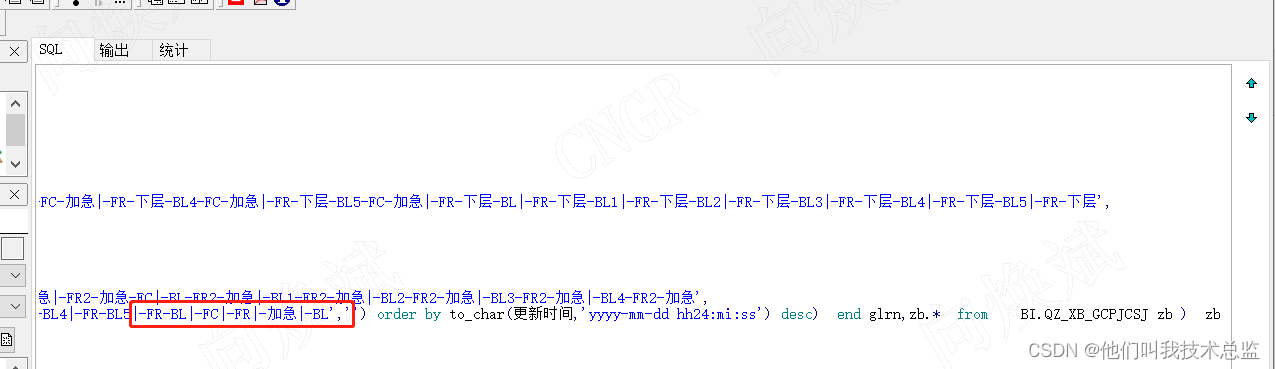
出来的数据还是有我们不想要的数据,比如下面的三个批次,我们只想保存一条,如果我们替换规则不当就会造成,这三个字符串替换后还是不相同的,无法达到我们想要的效果。

解决办法:我们首先将所有的替换规则用EXCEL表例好,然后排好优先级,然后再去修改正则表达式。如图所示我们将规则列好,然后用不同颜色标示优先级。然后再整理表达式。如下图所示小编将最小匹配项的表达式放到最后面了,这样就能达到我们想要的效果了。

四、总结
针对复杂的数据分析,首先建议从业务角度去规范,因为虽然技术可以处理,但是历史数据处理成本是巨大,因此一个企业的数据底座搭建,是离不开强标准化的数据治理的。