将原始数据中的字符串特征转化为模型可以识别的数字特征可是使用pandas自带的factorzie方法。
原始数据的job特征值如下
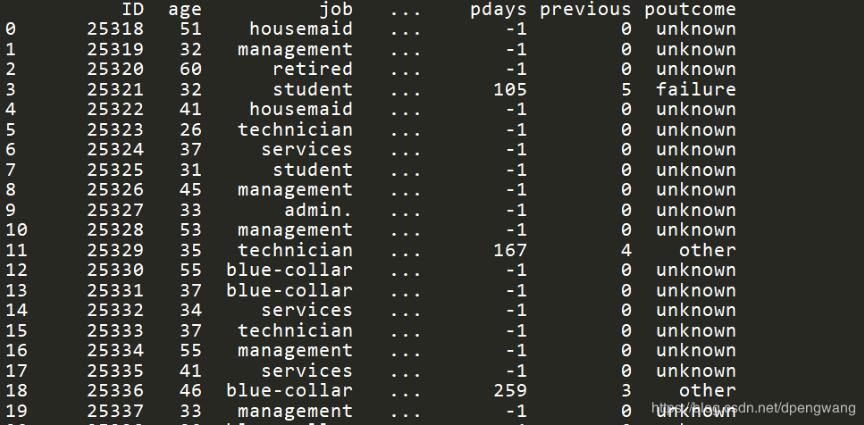
都是字符串特征,无法用于训练,当然可以单独建立map硬编码处理,但是pandas已经封装好了相应的方法。
data = pd.read_csv("data/test_set.csv")
data["job"] = pd.factorize(data["job"])[0].astype(np.uint16)
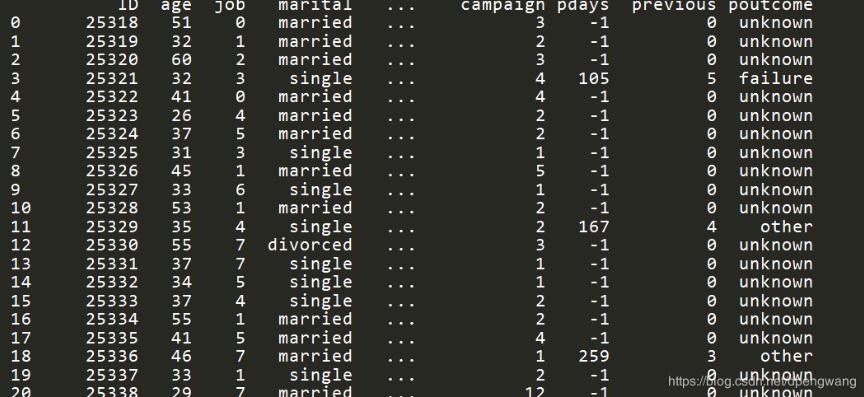
将原始数据中的字符串特征转化为模型可以识别的数字特征可是使用pandas自带的factorzie方法。
原始数据的job特征值如下
都是字符串特征,无法用于训练,当然可以单独建立map硬编码处理,但是pandas已经封装好了相应的方法。
data = pd.read_csv("data/test_set.csv")
data["job"] = pd.factorize(data["job"])[0].astype(np.uint16)