Swin Transformer
Swin Transformer是一种用于图像处理的深度学习模型,它可以用于各种计算机视觉任务,如图像分类、目标检测和语义分割等。它的主要特点是采用了分层的窗口机制,可以处理比较大的图像,同时也减少了模型参数的数量,提高了计算效率。Swin Transformer在图像处理领域取得了很好的表现,成为了最先进的模型之一。
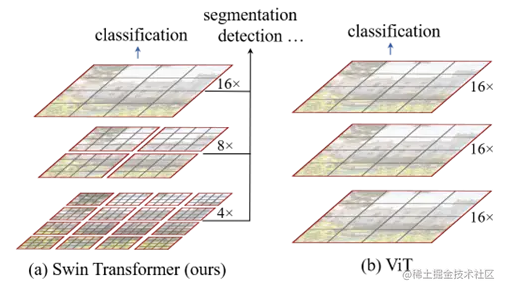
Swin Transformer通过从小尺寸的图像块(用灰色轮廓线框出)开始,并逐渐合并相邻块,构建了一个分层的表示形式,在更深层的Transformer中实现。
整体架构
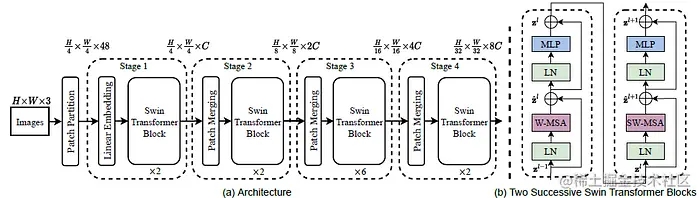

Swin Transformer 模块

Swin Transformer模块是基于Transformer块中标准的多头自注意力模块(MSA)进行替换构建的,用的是一种基于滑动窗口的模块(在后面细说),而其他层保持不变。如上图所示,Swin Transformer模块由基于滑动窗口的多头注意力模块组成,后跟一个2层MLP,在中间使用GELU非线性激活函数。在每个MSA模块和每个MLP之前都应用了LayerNorm(LN)层,并在每个模块之后应用了残差连接。
滑动窗口机制


Cyclic Shift
Cyclic Shift是Swin Transformer中一种有效的处理局部特征的方法。在Swin Transformer中,为了处理高分辨率的输入特征图,需要将输入特征图分割成小块(一个patch可能有多个像素)进行处理。然而,这样会导致局部特征在不同块之间被分割开来,影响了局部特征的提取。Cyclic Shift将输入特征图沿着宽度和高度方向分别平移一个固定的距离,使得每个块的局部特征可以与相邻块的局部特征进行交互,从而增强了局部特征的表达能力。另外,Cyclic Shift还可以通过多次平移来增加块之间的交互,进一步提升了模型的性能。需要注意的是,Cyclic Shift只在训练过程中使用,因为它会改变输入特征图的分布。在测试过程中,输入特征图的大小和分布与训练时相同,因此不需要使用Cyclic Shift操作。
Efficient batch computation for shifted configuration
Cyclic Shift会将输入特征图沿着宽度和高度方向进行平移操作,以便让不同块之间的局部特征进行交互。这样的操作会导致每个块的特征值的位置发生改变,从而需要在每个块上重新计算注意力机制。
为了加速计算过程,Swin Transformer中引入了"Efficient batch computation for shifted configuration"这一技巧。该技巧首先将每个块的特征值复制多次,分别放置在Cyclic Shift平移后的不同位置上,使得每个块都可以在平移后的不同的位置上参与到注意力机制的计算中。然后,将这些位置不同的块的特征值进行合并拼接,计算注意力。
需要注意的是,这种技巧只在训练时使用,因为它会增加计算量,而在测试时,可以将每个块的特征值计算一次,然后在不同位置上进行拼接,以得到最终的输出。
Relative position bias
在传统的Transformer模型中,为了考虑单词之间的位置关系,通常采用绝对位置编码(Absolute Positional Encoding)的方式。这种方法是在每个单词的embedding中添加位置编码向量,以表示该单词在序列中的绝对位置。但是,当序列长度很长时,绝对位置编码会面临两个问题:
- 编码向量的大小会随着序列长度的增加而增加,导致模型参数量增大,训练难度加大;
- 当序列长度超过一定限制时,模型的性能会下降。
为了解决这些问题,Swin Transformer采用了Relative Positional Encoding,它通过编码单词之间的相对位置信息来代替绝对位置编码。相对位置编码是由每个单词对其它单词的相对位置关系计算得出的。在计算相对位置时,Swin Transformer引入了Relative Position Bias,即相对位置偏置,它是一个可学习的参数矩阵,用于调整不同位置之间的相对位置关系。这样做可以有效地减少相对位置编码的参数量,同时提高模型的性能和效率。相对位置编码可以通过以下公式计算:

最终,相对位置编码和相对位置偏置的结果会被加到点积注意力机制中,用于计算不同位置之间的相关性,从而实现序列的建模。
代码实现:
下面是一个用PyTorch实现Swin B模型的示例代码,其中包含了相对位置编码和相对位置偏置的实现:
import torch
import torch.nn as nn
from einops.layers.torch import Rearrange
class SwinBlock(nn.Module):
def __init__(self, in_channels, out_channels, window_size=7, shift_size=0):
super(SwinBlock, self).__init__()
self.window_size = window_size
self.shift_size = shift_size
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
self.norm1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=window_size, stride=1, padding=window_size//2, groups=out_channels)
self.norm2 = nn.BatchNorm2d(out_channels)
self.conv3 = nn.Conv2d(out_channels, out_channels, kernel_size=1, stride=1, padding=0)
self.norm3 = nn.BatchNorm2d(out_channels)
if in_channels == out_channels:
self.downsample = None
else:
self.downsample = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
self.norm_downsample = nn.BatchNorm2d(out_channels)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.norm1(out)
out = nn.functional.relu(out)
out = Rearrange(out, 'b c h w -> b (h w) c')
out = self.shift_window(out)
out = Rearrange(out, 'b (h w) c -> b c h w', h=int(x.shape[2]), w=int(x.shape[3]))
out = self.conv2(out)
out = self.norm2(out)
out = nn.functional.relu(out)
out = self.conv3(out)
out = self.norm3(out)
if self.downsample is not None:
residual = self.downsample(x)
residual = self.norm_downsample(residual)
out += residual
out = nn.functional.relu(out)
return out
def shift_window(self, x):
# x: (B, L, C)
B, L, C = x.shape
if self.shift_size == 0:
shifted_x = torch.zeros_like(x)
shifted_x[:, self.window_size//2:L-self.window_size//2, :] = x[:, self.window_size//2:L-self.window_size//2, :]
return shifted_x
else:
# pad feature maps to shift window
left_pad = self.window_size // 2 + self.shift_size
right_pad = left_pad - self.shift_size
x = nn.functional.pad(x, (0, 0, left_pad, right_pad), mode='constant', value=0)
# Reshape X to (B, H, W, C)
H = W = int(x.shape[1] ** 0.5)
x = Rearrange(x, 'b (h w) c -> b c h w', h=H, w=W)
# Shift window
x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(2, 3))
# Reshape back to (B, L, C)
x = Rearrange(x, 'b c h w -> b (h w) c')
return x[:, self.window]
class SwinTransformer(nn.Module):
def __init__(self, in_channels=3, num_classes=1000, num_layers=12, embed_dim=96, window_sizes=(7, 3, 3, 3), shift_sizes=(0, 1, 2, 3)):
super(SwinTransformer, self).__init__()
self.in_channels = in_channels
self.num_classes = num_classes
self.num_layers = num_layers
self.embed_dim = embed_dim
self.window_sizes = window_sizes
self.shift_sizes = shift_sizes
self.conv1 = nn.Conv2d(in_channels, embed_dim, kernel_size=4, stride=4, padding=0)
self.norm1 = nn.BatchNorm2d(embed_dim)
self.blocks = nn.ModuleList()
for i in range(num_layers):
self.blocks.append(SwinBlock(embed_dim * 2**i, embed_dim * 2**(i+1), window_size=window_sizes[i%4], shift_size=shift_sizes[i%4]))
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(embed_dim * 2**num_layers, num_classes)
# add relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * (2 * window_sizes[-1] - 1), embed_dim // 8, embed_dim // 8)),
requires_grad=True)
nn.init.kaiming_uniform_(self.relative_position_bias_table, a=1)
# add relative position encoding
self.pos_embed = nn.Parameter(
torch.zeros(1, embed_dim * 2**num_layers, 7, 7),
requires_grad=True)
nn.init.kaiming_uniform_(self.pos_embed, a=1)
def forward(self, x):
out = self.conv1(x)
out = self.norm1(out)
out = nn.functional.relu(out)
for block in self.blocks:
out = block(out)
out = self.avgpool(out)
out = Rearrange(out, 'b c h w -> b (c h w)')
out = self.fc(out)
return out
def get_relative_position_bias(self, H, W):
# H, W: height and width of feature maps in the last block
# output: (2HW-1, 8, 8)
relative_position_bias_h = self.relative_position_bias_table[:,
:(2 * H - 1), :(2 * W - 1)].transpose(0, 1)
relative_position_bias_w = self.relative_position_bias_table[:,
(2 * H - 1):, (2 * W - 1):].transpose(0, 1)
relative_position_bias = torch.cat([relative_position_bias_h, relative_position_bias_w], dim=0)
return relative_position_bias
def get_relative_position_encoding(self, H, W):
# H, W: height and width of feature maps in the last block
# output: (1, HW, C)
pos_x, pos_y = torch.meshgrid(torch.arange(H), torch.arange(W))
pos_x, pos_y = pos_x.float(), pos_y.float()
pos_x = pos_x / (H-1) * 2 - 1
pos_y = pos_y / (W-1) * 2 - 1
pos_encoding = torch.stack((pos_y, pos_x), dim=-1)
pos_encoding = pos_encoding.reshape(1, -1, 2)
pos_encoding = pos_encoding.repeat(1, 1, embed_dim // 2)
pos_encoding = pos_encoding.transpose(1, 2)
return pos_encoding